[MLops] - overview
MLops 필요성
model의 유지보수 및 관리에는 Data, Model, Code를 고려해야한다. 아래 그림을 참고하면 model을 배포할 때, model 외에 다양한 요소가 있어 모두 고려해야 신뢰성 높은 시스템을 구축할 수 있다는 것을 알 수 있다.
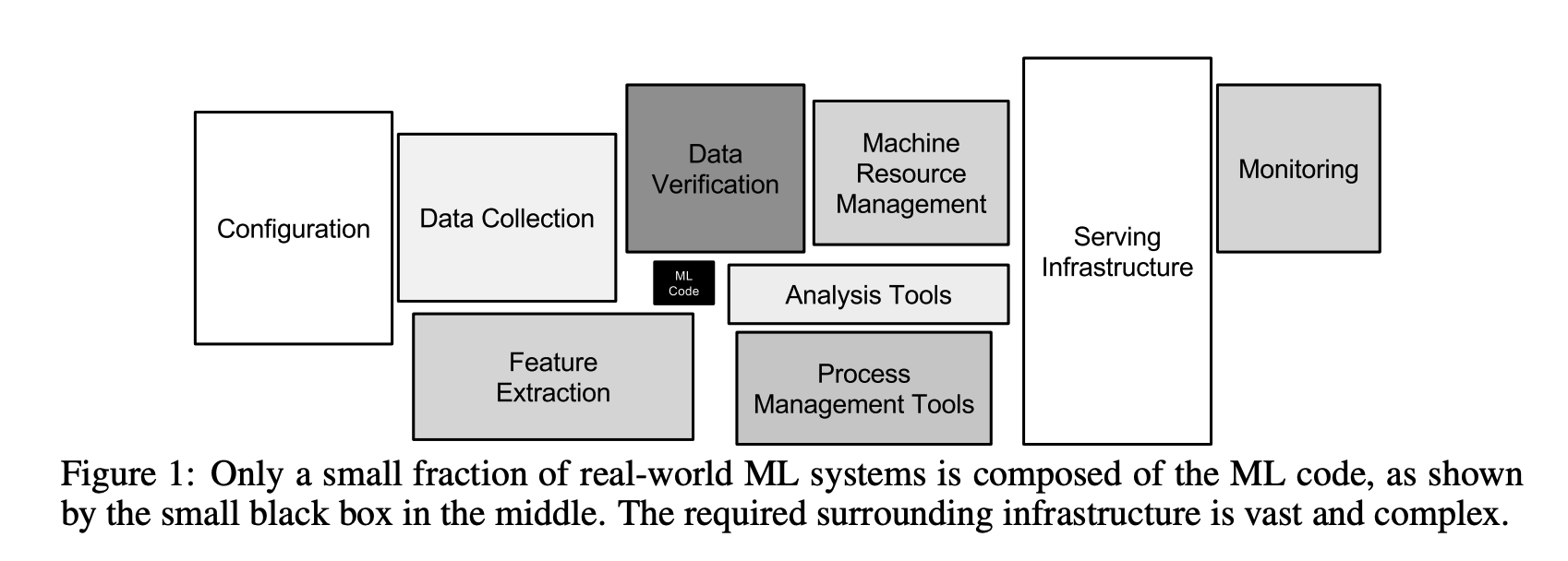 출처 : neurips 2015 Hidden Technical Debt in Machine Learning Systems
출처 : neurips 2015 Hidden Technical Debt in Machine Learning Systems
ML project lifecycle
- Scoping : 어떤 문제를 풀고싶고, 무슨 데이터가 필요하고, 어느 성능을 원하는지 등 정의 시스템의 스펙 정의가 중요하다. (latency, accuracy, throughput) Define project
- Data : 데이터 수집 및 라벨링 일관성 있는 전처리가 중요하다. Define data and establish baseline Label and organize data
- Modeling : 모델링 및 성능평가 Select and train model Perform error analysis
- Deployment : 배포 및 시스템 모니터링 Deploy in production Monitor & maintain system - software engineering issue checklist a. realtime vs batch b. cloud vs edge/browser c. compute resources (CPU/GPU/memory) d. Latency, throughput e. Logging f. Security and privacy
Deployment - monitoring
Concept drift
x(입력), y(출력) 사이의 관계 변경
a. 점진적 변경 예시 - 장비의 기계적 마모, 거시경제의 변화
b. 급진적 변경 예시 - COVID, 생산라인의 장비 변경, 앱인터페이스변경(클릭률 의미가 바뀜) c. 계절성 변경 예시 - 평일/주말의 구매패턴Data drift x(입력)의 통계치 변화 mean, variance, 등 데이터 분포가 바뀜
metric to monitor software metric (system memory, cpu load) input metric (mean, variance, …) output metric (여러 모델이 결합된 경우 서로 영향을 줄 수 있기에 중요) 예를 들어, 모델 1 (음성을 감지하고 전처리) 후에, 모델 2 (분류)하는 과정
Deployment - case
- shadow : 인간의 역할이 주, 모델의 결과는 사용되지 않음
- canary : 적은 비율 (예를들어 5%)부터 ramp up gradually
- blue-green : old model을 blue, new model을 green으로 두고 배포하여 신속한 배포가 가능하고, rollback이 가능
References
1 : https://towardsdatascience.com/machine-learning-in-production-why-you-should-care-about-data-and-concept-drift-d96d0bc907fb
2 : coursera - MLops specialization courese
3 : https://christophergs.com/machine%20learning/2020/03/14/how-to-monitor-machine-learning-models/
